3. 関係データモデル#
関係データベース(relational database) とは,関係データモデルにもとづき表現されたデータの集まりです. 前講で述べたように,関係データモデルとは,表によってデータを表現するデータモデルです. 一見すると単純な表にしか見えない関係データモデルは数学によって定式化されており,強固な理論的基盤を有しています. 関係データモデルを用いることで,データから冗長性を排除し,データを正しく管理することが可能となります.
以下では,数学的な観点から関係データモデルについて述べます. 少々堅い説明にはなりますが,関係データベースという計算機科学技術が数学に支えられていることを知るためにも,眠気を我慢して読んでください. なお,本講では数学における「集合と写像」の知識を使います. 最低限の知識をコチラにまとめたので,不安がある方はそちらを参照してください.
Note
計算機科学とは抽象化の学問
計算機科学(あるいは情報科学)というと「プログラミングでしょ」と考える学生は多いですが,それは間違いです. 計算機科学の本質は,物事を計算可能な状態にする(抽象化)し,計算機の上で処理・分析することにあります. データベースもその一つです. 計算機科学は抽象化の学問なのです.
3.1. 関係データモデルのデータ構造#
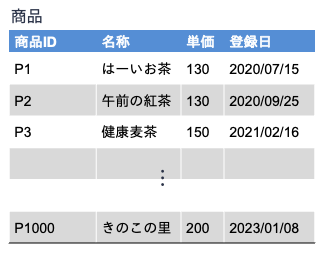
上の表は,ある小売店で取り扱っている商品のデータを関係データモデルによって表現したものです. この表において,各行は小売店で取り扱っている商品に対応し,各列には各商品に関するデータが記述されています.
表の左上にある「商品」はこの表の名前を示しており,関係名と呼ばれます. 関係データモデル上では,各行はタプル(tuple) と呼ばれます. 表の1行目には,「商品」がどのようなデータを持つかを示す見出しが付けられています. 表における各見出しに対応するものを,関係データモデルでは属性(attribute) と呼びます. また,各タプルにおけるある属性の値を属性値と呼びます. 例えば,表中の2行目に対応するタプルは
(“P1”, “はーいお茶”, 130, “2020/07/15”)
ですが,このタプルの属性「単価」の属性値は130となります.
3.1.1. 数学における「関係」#
ところで,関係データベースあるいは関係データモデルの「関係」とは一体何でしょうか. 関係(relation) とは数学上の概念です. 集合\(S_1, S_2, ..., S_n\)が与えられたとき,それらの直積集合\(S_1 \times ... \times S_n\)とは
\(S_1 \times ... S_n = \{(x_1, ..., x_n) \ | \ x_1 \in S_1, ..., x_n \in S_n \}\)
と表現されるものです(直積の概念を忘れた方はコチラを確認してください)(★Quiz1★). (数学上の概念である)関係とは,このような直積集合の部分集合を意味します. 正確に書くと,集合\(S_1, S_2, ..., S_n\)が与えられたとき,直積集合\(S_1 \times ... \times S_n\)の部分集合を\(S_1, S_2, ..., S_n\)上のn項関係と呼びます.
例えば,\(A=\{2, 3\}\),\(B=\{-2, -3\}\)が与えられたとき,直積\(A \times B\)は集合AおよびBの要素のすべての組み合わせであるから
\(A \times B = \{(2, -2), (2, -3), (3, -2), (3, -3)\}\)
となります. このとき,その部分集合の1つである
\(\{(2, -3), (3, -2)\}\)
は集合AおよびB上の2項関係となります. このような(n項)関係の概念を使って,関係データモデルは理論構築されています(★Quiz2★).
3.1.2. 関係データモデルにおける「関係」#
関係データモデルにおける関係は「数学におけるの関係」を拡張したものになっており,以下の2つから構成されます.
関係スキーマ
インスタンス
関係スキーマ(relation schema) とは,関係の名前と属性の集合,および(後述する)一貫性制約の情報を示すものです. 関係スキーマは
\((\boldsymbol{R}(A_1, ..., A_n), \{\sigma_1, \sigma_2, ..., \sigma_m\})\)
の形式で記述されます. ここで
\(\boldsymbol{R}\)は関係名
\(A_1, ..., A_n\)は属性
\(\sigma_1, ..., \sigma_m\)は一貫性制約
に対応します. 一貫性制約が自明な場合やそれを考慮しないときは,関係スキーマを
\(\boldsymbol{R}(A_1, ..., A_n)\)
のように簡潔に表記することもあります. 先の表「商品」の例の場合,関係スキーマは
\(商品(商品ID, 名称, 単価, 登録日)\)
と記述します(★Quiz3★).
関係スキーマに記された各属性には,属性が取り得る値の集合を定義します. この集合はドメイン(domain; 定義域) と呼ばれ,属性\(A\)のドメインは\(Dom(A)\)と記します. 例えば,先の表「商品」の例では,属性「単価」は金額を表すので,そのドメイン\(Dom(単価)\)は0以上の整数値が想定されます. これを数学的に記すと,以下のようになります:
\(Dom(単価) = \{ x \ | \ x \in \mathbb{N} \}\)
同様に,属性「商品ID」「名称」「登録日」についても,以下のようにドメインを定義できます.
\(Dom(商品ID) = \{ x \ | x \in Pから始まる文字列集合 \}\)
\(Dom(名称) = \{ x \ | \ x \in 文字列集合 \}\)
\(Dom(登録日) = \{ x \ | \ x \in 年月日集合(ただし西暦表記) \}\)
インスタンス(instance) は,関係スキーマ\(\boldsymbol{R}(A_1, ..., A_n)\)におけるドメイン\(Dom(A_1), ..., Dom(A_n)\)の直積の部分集合です. 仮にインスタンスを\(R\)とすると,
\(R \subset{Dom(A_1) \times ... \times Dom(A_n)}\)
です. インスタンスは,上で説明した数学上の関係に相当します(あらためて「数学における関係」の節を確認してみましょう). また,インスタンス\(R\)の要素がタプルとなります.
例に戻って,定義と照らし合わせてみましょう. 先の表「商品」の関係スキーマは\(商品(商品ID, 名称, 単価, 登録日)\)でした. 各属性のドメインの定義も与えましたが,その定義から,例えば属性「単価」については
\(Dom(単価) = \{1, 2, 3, .... 10000, .... \}\)
のようにあらゆる自然数を取り得ます. また,属性「名称」については
\(Dom(名称) = \{"あ", "い", ..., "はーいお茶", ... \}\)
のようにあらゆる文字列を取り得ます.
各属性の直積\(Dom(商品ID) \times Dom(名称) \times Dom(単価) \times Dom(登録日)\)には,
(“P001”, “こんな商品はありません”, 100兆, “2020/01/01”)
のように,実際に商品情報としてありえないタプルも含めて,様々なタプルが要素として含まれます. なぜなら,直積とは集合(ドメイン)の要素のすべての組み合わせであるためです. ドメインの直積の部分集合をインスタンスとすることは,取り得るタプルの候補から実際にデータとして扱われるタプルの集合を選択することに相当します(★Quiz4★).
Warning
タプルは重複が許されない
一般的に使われる表では,同じ内容を表す行が複数あっても許されます. 一方,関係データモデルに基づく表は行,すなわちタプルの重複は許されません. なぜなら,関係データモデルのインスタンスは(数学的な)集合だからです.
3.2. 非正規関係と第1正規形#
関係データモデルにおけるドメインとは属性が取り得る値の集合を意味しますが,ドメインの要素はそれ以上分解不可能な値を意味する原子値(atomic value) であることを想定しています. 原子値の例としては,文字列,整数,実数,真偽値,日付などが挙げられ,どれもデータの基本単位と呼べるものです. 逆に原子値で「ない」例としては,タプルや集合,関係などが挙げられます. ドメインとして原子値以外の値をとることを許す関係データを非正規関係(unnormalized relation) と呼びます. 逆に,ドメインとして原子値しかとらない関係は第1正規形(first normal form; 1NF)である といいます.
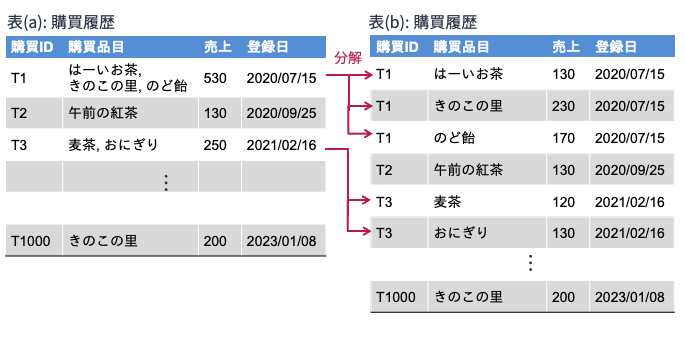
例えば,以下の表(a)(b)はともに商品の購買履歴を表していますが,表(a)は属性「購入品目」に集合要素が入ってしまっています(例えば,{"はーいお茶", "きのこの里", "のど飴"}).
表(a)の属性「購入品目」のドメインが原子値以外の値(つまり文字列の集合)を許してしまっていることから,表(a)は非正規関係と見なせます.
一方,表(b)は表(a)の購買品目の値が原子値(文字列の集合ではなく文字列)になるように設計されているため,第1正規形と見なせます. 表(a)では1行で表現できていた1回分の購買データが,表(b)では複数行を使って表現されています. 表(b)のほうがデータ構造が簡潔になるため,データが扱いやすいです.
3.3. 一貫性制約#
一貫性制約(integrity constraint) とは,データベースが対象とする実世界を反映するように設定された,データが満たすべき規則です. 関係データモデルにおいては,代表的な一貫性制約として以下があります:
ドメイン制約
キー制約
参照制約
データ従属性
関係データモデルを扱うデータベースを設計する際には,上記一貫性制約を踏まえて関係スキーマの定義や(複数の関係スキーマへの)分解 を行います.
3.3.1. ドメイン制約#
ドメイン制約(domain constraint) とは,関係\(\boldsymbol{R}(A_1, ..., A_n)\)に含まれるタプルの各成分は,対応する属性のドメインの要素でなければならならいという制約です. これは属性の定義ですでに触れたことです. ドメイン制約では,各属性のドメインのデータ型(例: 整数,実数,文字列,日付)に加えて,値が取り得る範囲を指定することもあります. 例えば,
先の例でとりあげた関係
\(商品(商品ID, 名称, 単価, 登録日)\)
において,属性「単価」や「登録日」のドメインは
\(Dom(単価) = \{ x \ | \ x \in \mathbb{N} \}\)
\(Dom(登録日) = \{ x \ | \ x \in 年月日集合(ただし西暦表記) \}\)
のように定義されていました. これらはドメイン制約です. これら制約にもとづき,
「単価」属性の値は必ず自然数
「登録日」属性の値は必ず西暦表記の年月日集合
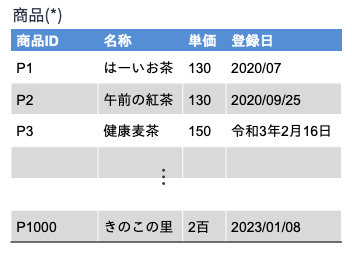
でなければなりません. よって,以下の関係「商品(*)」は関係「商品(商品ID, 名称, 単価, 登録日)」のインスタンスにはなれません. なぜなら,
商品IDがP1の商品の登録日は年月はあるが日が抜けている
商品IDがP3の商品の登録日は和暦で表現されている
商品IDがP1000の商品の単価は漢数字(文字列)で表現されている
からです(★Quiz5★).
3.3.2. キー制約#
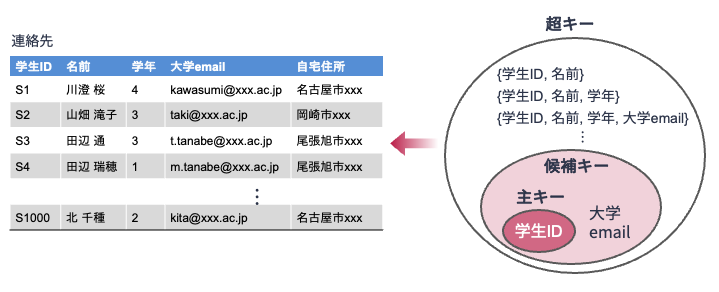
まず,キー制約の前提となるキーの概念について説明します. 関係\(\boldsymbol{R}\)における超キー(super key) とは,関係\(\boldsymbol{R}\)における属性の集合のうち,それらの属性値が決まればおのずと関係\(\boldsymbol{R}\)のタプルが唯一ひとつに決まる(タプルを一意に特定できる)ものを指します.
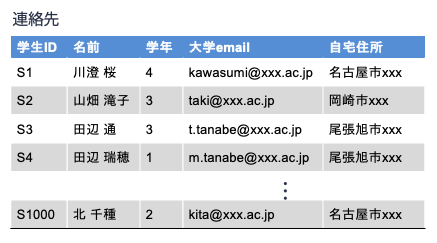
例えば,以下の表は関係スキーマ
\(連絡先(学生ID, 名前, 学年, 大学email, 自宅住所)\)
に従うデータを表形式で記したもので,各行(タプル)は学生の連絡先情報を示しています. 大学において学生情報を管理する場合,学生ID(の値)が決まれば唯一1つの学生連絡先情報(行; タプル)を照会できるよう,学生IDは重複がないように設定されます. それゆえ,この関係「連絡先」において属性「学生ID」は超キーとなります. 同様に,属性「大学email」も超キーとなります.
なお,{ 学生ID, 名前 },{ 学生ID, 名前, 学年 } のように学生IDを含む属性の集合も超キーになります.
例えば,「学生ID」がS1,「名前」が川澄桜である行は唯一1行に決まるので,属性集合 { 学生ID, 名前 } も超キーになります.
これは属性「学生ID」が超キーであるから,当たり前です.
一方,属性「住所」は超キーにはなり得ません.
学生IDがS3とS4の学生の住所が同じ(つまり同じところに住んでいる)であるから,住所を1つ指定しても連絡先タプルが一意に特定できないからです.
超キーは複数ありえますが,上の例では属性「学生ID」のみでタプルを特定できるように,属性集合 { 学生ID, 名前 } を使ってタプルを特定しようとするのは無駄でしょう. そこで,超キーのうち極小(つまり最も小さい部分集合)のものを候補キー(candiate key) と定義します. 候補キーは単純にキー(key) と呼ばれることもあります. 例えば,上の関係「連絡先」では,属性「学生ID」や「大学email」が候補キーとなりえます(★Quiz6★).
最後に主キー(primary key) の概念を導入します. 候補キーのうち,値として未定義や空の値(空値またはNULL値と呼ばれる) を取る可能性がなく,かつデータベース管理上都合のよいキーの1つを主キーと決めます. 主キー以外の候補キーは代替キーと呼ばれます. 例えば,先の関係「連絡先」の場合,候補キーは「学生ID」と「大学email」でしたが,大学emailは「氏名@xxx.ac.jp」のようなものから「学籍番号@xxx.ac.jp」のようなものに変更される可能性があったとしても,学生IDは一度決めたらほぼ変わらないと思われます. これらを鑑みると,関係「連絡先」においては属性「学生ID」を主キーとして選ぶのがよさそうです.
なお,候補キーの定義から主キーは属性の集合をとることができます. このような主キーを複合主キー(composite primary key) と呼びます.
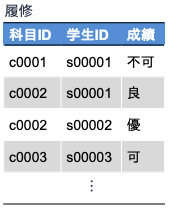
例えば,上の表は,学生が履修した科目の成績をあらわす関係「履修」を表にしたものです. この表においては科目IDあるいは学生IDだけでは成績が特定できませんが,科目IDと学生IDの両方が決まれば,ある学生のある科目の成績が特定されます. それゆえ,関係「履修」においては { 科目ID, 学生ID } の属性ペアが主キーとなります(★Quiz7★).
関係表と主キー,候補キー,超キーの関係は,以下の図のようにまとめることができます.
ここまで,超キー,候補キー,主キーの説明を行いましたが,最後に本節の主題であるキー制約について述べます. キー制約(key constraint) は,関係\(\boldsymbol{R}\)の関係スキーマに対して主キーが設定されたとき,\(\boldsymbol{R}\)のインスタンスにおいて
主キーに設定された属性の値は重複があってはならない,かつ
その要素(タプル)は主キーによって一意に特定されなければならない,かつ
主キーとなる属性の値はNULL値 であってはならない
という制約です. 定義は小難しく見えるかもしれませんが,キー制約は「ある属性が主キーと設定されたら,それがきちんと主キーの役割を果たすようデータが作られなければならない」ということを意味しています. 主キーを定義できれば,キー制約を定義できたようなものです.
さて,関係スキーマにおいてキー制約以外の一貫性制約には注目しない場合,関係スキーマでは主キーは以下のように下線を引いて表します.
\(\boldsymbol{R}(\underline{A_1, A_2}, ..., A_n)\)
例えば,上の図の関係「連絡先」であれば,その関係スキーマは以下のように表します.
\(連絡先(\underline{学生ID}, 名前, 学年, 大学email, 自宅住所)\)
Important
キーは関係スキーマに対して設定される
キーは,関係データベース内にあるタプル(行)だけを見て決めてはいけません. 例えば上の例の関係「連絡先」の場合,表の見えているところだけに注目すると,属性「名前」もキーに見えます. しかし,現実的には同性同名の学生が存在しうるでしょう. そのため,「名前」をキーにすると,連絡先のタプルを一意に特定できない可能性が生じます(キーの性質を失います).
そもそも関係データモデルにおいては,どのようなデータをデータベースに格納する可能性があるかを事前に想定して関係スキーマを設定します(その中にキーの設定も含まれます). その上で,設定した関係スキーマに従ってデータを生成し格納します. 決してインスタンスを見てキーを決めるわけではありません. キーは「関係スキーマに対して設定される」ことを意識しましょう.
3.3.3. 参照整合性制約#
(関係データモデルにもとづく)関係データベースでは,対象となる事象のデータを正しく管理するために,データを複数の関係(表)で管理することがほとんどです. 複合主キーの説明の例で使った関係「履修」には,その値だけ見ても具体的に何を意味しているのかが分からない属性「科目ID」「学生ID」があります. これらの意味を読み解くためには
「科目ID」がどのような科目のことを指しているのか
「学生ID」がどの学生のことを指しているのか
といった情報を管理する他の関係(表)が必要となります. 以下の図は,学生の成績を管理するための関係データベースの例です. この中には関係「履修」も含まれています.
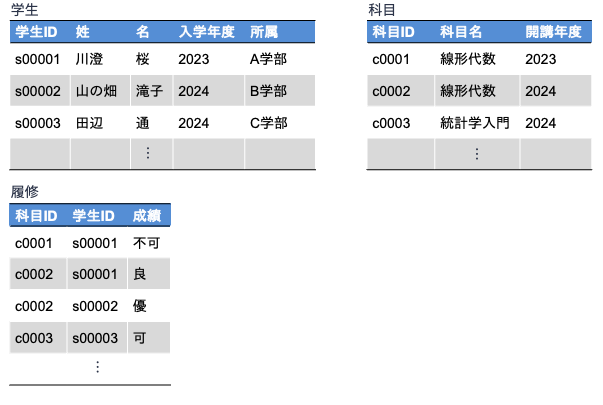
上記3つの関係(表)があれば,
関係「学生」から「学生ID」が
s0001のものを探し,関係「科目」から「科目ID」が
c0001のものを探す
ことで,関係「履修」において「学生ID」がs0001で「科目ID」がc0001の「成績」が不可だった件について,具体的にどんな学生が何の科目を落としてしまった(不可になってしまった)かを把握することができます.
このとき,関係「履修」のタプルにある「科目ID」のc0001という値が,関係「科目」のインスタンスの属性「科目ID」に含まれていなければなりません(関係「科目」の科目IDの列にその値が存在しなければなりません),ということは自明でしょう.
関係「履修」の中にはあるが,関係「科目」には存在していなければ,データ管理として破綻していることになります.
「学生ID」のs0001についても同様です.
上記の例では,
関係「履修」の属性「学生ID」は関係「学生」の主キーである「学生ID」と
関係「履修」の属性「科目ID」は関係「科目」の主キーである「科目ID」と
紐付いていることが分かります. 言い方を変えると,関係「履修」は属性「学生ID」および「科目ID」の値を通して,関係「学生」および「科目」の情報を参照していることになります.
このように,関係スキーマ\(\boldsymbol{R_1}(..., FK, ...)\)と\(\boldsymbol{R_2}(\underline{PK}, ...)\)が与えられ,\(R_1\)におけるタプルの属性\(FK\)の値は必ず\(R_2\)におけるいずれかのタプルの主キー\(PK\)の値と一致するように設計されているとき,\(R_1\)の属性\(FK\)を\(R_2\)の\(PK\)に対する外部キー(foreign key) と呼びます. 関係スキーマ上では,関係\(\boldsymbol{R_1}\)の属性\(FK\)が関係\(\boldsymbol{R_2}\)の主キー\(PK\)に対する外部キーであることを以下のように記します.
\(\boldsymbol{R_1}.FK \subseteq \boldsymbol{R_1}.PK\)
先の例では,関係「履修」の属性「学生ID」および「科目ID」が外部キーとなるので,関係スキーマとして
\(履修.学生ID \subseteq 学生.学生ID\)
\(履修.科目ID \subseteq 科目.科目ID\)
と記します(★Quiz8★).
前置きが長くなりましたが,本節のテーマである参照制約(referential constraint) とは「関係スキーマにおいて外部キーが設定されたとき,そのいかなるインスタンスも設定された外部キーの条件を満たさなければいけない」という制約です.
3.3.4. データ従属性#
一貫性制約として,ドメイン制約,キー制約,参照制約を挙げてきました. 関係データモデルにはこれら以外にも,データ間に成立する制約を数学的に記述する手段があります. これをデータ従属性(data dependency) と呼びます.
データ従属性としては,関数従属性,多値従属性,結合従属性など,様々なものが提案されています. 関数従属性(functional dependency) は,データ従属性の中でも最も単純で,かつ実用的なものです. 関数従属性は,「関係\(\boldsymbol{R}(..., X, ..., Y, ...)\)において,属性(あるいは属性集合)\(X\)の値が決まると属性\(Y\)の値も一意に決まる」という性質です. このことを
\(X \to Y\)
と記します.
例えば,関係として
\(連絡先(\underline{学生ID}, 名前, 学年, 大学email, 郵便番号, 都道府県, 自宅住所)\)
が与えられたとしましょう. 一般常識から,住所が決まればそれが存在する都道府県や郵便番号もひとつに決まります. このことから,関係「連絡先」においては
\(自宅住所 \to 郵便番号\)
\(自宅住所 \to 都道府県\)
という関数従属性が定義できます. 関数従属性はキー制約を一般化したものと捉えることができます.
データ従属性は,データの更新があったときにその影響が最小限になるように関係データベースを設計する上で,極めて重要です. それゆえ,特に関数従属性については別の講で取り上げます.
3.4. クイズ#
3.4.1. Q1. 直積#
集合\(S_{lang}\),\(S_{popularity}\),\(S_{difficulty}\)を以下のように定義します:
\(S_{lang} = \{Python, R, C^{++}\}\)
\(S_{popularity} = \{人気, 不人気\}\)
\(S_{difficulty} = \{難, 普通, 易\}\)
このとき,直積集合\(S_{lang} \times S_{popluarity} \times S_{difficulty}\)の要素をすべて列挙してください.
3.4.2. Q2. 関係#
Q1で定義した集合\(S_{lang}\),\(S_{popularity}\),\(S_{difficulty}\)上の3項関係を適当に考えてください.
※ 正解は一意に決まらないので,深く悩まずクイズに取り組んでください.
3.4.3. Q3. 関係スキーマ#
関係スキーマ
\(学生(学籍番号, 氏名, 学部, 年齢, 出身都道府県)\)
に従う表データの例を作成してください. なお,表の行数は見出し行を含めて5-6行程度でよいです.
3.4.4. Q4. ドメイン#
Q3で定義した関係スキーマ「学生」の各属性について,そのドメインを定義してください.
\(Dom(学籍番号) = \{ ... \}\)
の形式で頑張って書いてみてください.
3.4.5. Q5. ドメイン制約#
Q4で定義した関係スキーマ(ドメイン定義を含む)に対して,ドメイン制約に違反しているタプルの例を2,3個列挙してください.
3.4.6. Q6. 候補キー(令和4年度 ITパスポート試験 問65改題)#
関係スキーマ
\(従業員(従業員番号, 従業員名, 部門コード, 生年月日, 住所)\)
において,候補キーは何でしょうか. なお,関係「従業員」は以下のような制約条件をもちます:
各従業員は重複のない従業員番号を1つだけもつ
同姓同名の従業員がいてもよい
各部門は重複のない部門コードを1つだけもつ
1つの部門には複数名の従業員が所属する
1人の従業員が所属する部門は1つだけである
3.4.7. Q7. 主キー#
以下の表「会員管理」において,想定される主キーは何でしょうか.
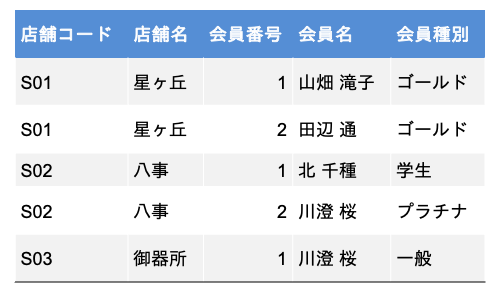
3.4.8. Q8. 参照整合性制約#
以下の関係スキーマをもつ5つの関係からなるデータベースにおいて,定義すべき参照整合性制約をあげてください.
\(顧客(\underline{顧客ID}, 氏名, 性別)\)
\(店舗(\underline{店舗ID}, 店舗名, 住所)\)
\(商品(\underline{商品ID}, 商品名, 商品カテゴリID, 単価)\)
\(購買(\underline{購買ID}, 店舗ID, 顧客ID, 商品ID, 個数, 購買日)\)
\(商品カテゴリ(\underline{商品カテゴリID}, カテゴリ名)\)