15. NoSQL#
これまで計14回に渡って学んできた関係データベースは,データの重複や矛盾を排除し,データ間の整合性を保つことを重視したデータベース技術です. 関係データベースはその特性から,
データの構造を(事前に)きっちりと定義できるケース
データを正しく保つことが求められるケース
において特に真価を発揮します. そのため,顧客管理,在庫管理,購買管理などのビジネス現場において重宝されています.
関係データベースは1970年頃に生まれた技術ですが,今日においてもデータベースの中心的な存在です. しかしながらビッグデータ時代においては,従来の関係データベースでは扱いきれないデータ処理事例が発生しています. NoSQL [1]は,関係データベースがもつ特性を一部犠牲にすることで,関係データベースでは扱いきれないデータ処理事例に対応するためのデータベース技術の総称です.
以下,NoSQLについて簡単に解説します. なお,NoSQLは関係データベースを補完する技術であり,NoSQL(あるいは関係データベース)のほうが優れているというわけではありません. ケースに応じて関係データベースとNoSQLを使い分けることが重要です.
15.1. ビッグデータを扱うためにデータベースに求められること#
一般に,ビッグデータは以下のような3つの性質を満たすデータの集合を指します:
High volume: 扱うデータの「量」が多い
High variety: 扱うデータの「種類」が多い
High velocity: 扱うデータが「生成される速度」が速い
関係データベースシステムは計算機の上で動くソフトウェアです. そのため,CPUやメモリ,二次記憶装置といった計算機などのコンポーネントを強化することで,関係データベースのパフォーマンスを向上させることが可能です(このアプローチをスケールアップ あるいは垂直方向のスケーリング と呼びます). しかしながら,関係データベースの「データを正しく管理することに特化した設計」が仇となり,データの量や種類,生成速度が「圧倒的に大きい」ビッグデータに対しては,スケールアップした関係データベースですら処理が間に合わないことがあります.
データベースへの膨大な問い合わせを処理する方法の一つは,データベースのコピーや分割したものを複数の計算サーバ上に配置することで,サーバの稼働状況や負荷状況に応じて問い合わせ処理を振り分ける(分散させる)といった方法です. このように,1つの計算機をパワーアップさせるのではなく,計算サーバを増やすことで総体としてサービスのパフォーマンスを高めるアプローチをスケールアウト あるいは水平方向のスケーリング と呼びます.
ウェブ検索エンジンやソーシャルゲーム,SNSといったビッグデータを扱うサービスにおいては,「データの正しさを厳密に保つこと」よりも「膨大かつ多様な種類のデータを安定的・高速に処理できること」が優先されます. NoSQLはデータの正しさ(特に,データが常に最新であること)の管理を一部妥協することで,(スケールアップではなく)スケールアウトによってビッグデータ処理を実現します. また,データ構造をガチガチに固定する関係データベースとは対照的に,NoSQLは複雑かつ多様なデータを柔軟に扱うための工夫を有しています.
15.2. 様々なNoSQL#
NoSQLは単一のデータベース技術ではありません. 関係データベースの欠点を補うために,様々なタイプのNoSQLデータベースが開発されています. 最も一般的なNoSQLデータベースは,以下の4つです.
キー・バリュー型データベース
列指向データベース
ドキュメント指向データベース
グラフデータベース
重要なのは,それぞれのNoSQLデータベースの特徴を押さえて,ケースに応じてNoSQLデータベースと関係データベースを使い分けることです.
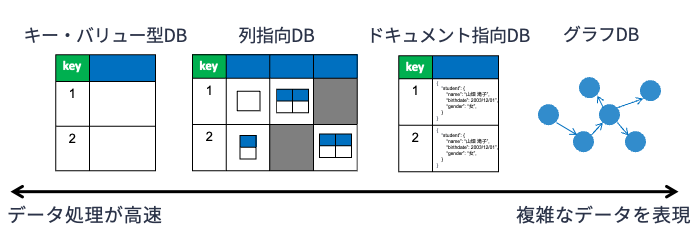
15.2.1. キー・ストア型データベース#
キー・バリュー型データベース(key-value store database; KVS database) は,以下の図のように重複のない(一意の)キーとデータの値(バリュー)のペアを格納する,非常にシンプルな構造のデータベースです. キー・バリュー型データベースはキーとバリューという2つの属性からなる関係データを扱っているように見えますが,関係データベースのようにデータに厳密な制約条件を設けません. また,問い合わせもキーの値を直接指定し,それに対応するバリューの値を受け取る ことに特化しています.
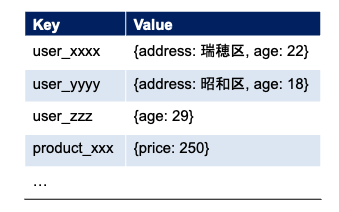
このように,キー・バリュー型データベースはデータ構造を単純化し,問い合わせ形式を限定することで,データ処理を超高速化しています. 一方,複数のテーブルにまたがるデータの結合が必要となるケースには適していません. 代表的なキー・バリュー型データベースとしては,RedisやAmazon DynamoDBなどがあります.
15.2.2. 列指向データベース#
列指向データベース(column-oriented database) は,キー・バリュー型データベースを拡張したようなNoSQLデータベースです.
列指向データベースはワイドカラムデータベース(wide-column database) あるいはカラムファミリーデータベース(column-family database) と呼ばれることもあります.
以下の図のように,列指向データベースではデータをキーとバリューからなるペアとして管理します.
キー・バリュー型データベースとの違いは,バリューとしてカラムファミリーと呼ばれるキー・バリュー構造のデータを持つことができる点です.
例えば,図中のキーがcxxx0001のデータの価格の値を取得したい場合は,キーの値とカラムファミリー名を指定すればよいです.
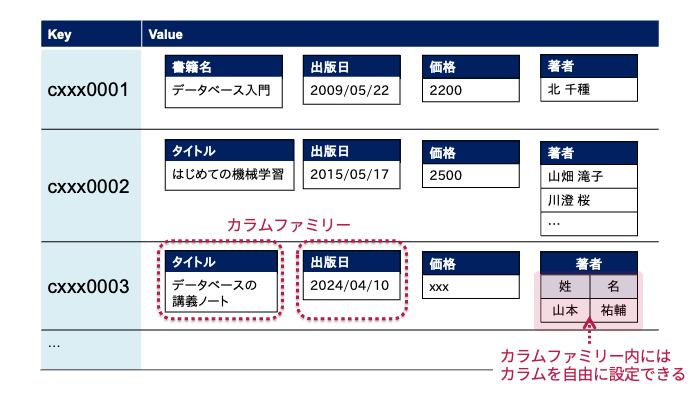
なお,カラムファミリーの中には,同じくキー・バリュー構造のカラムを複数もつことができます.
例えば,上図においてキー値がcxxx0003のデータは,著者カラムファミリーの中に姓というカラムと名というカラムを持っています.
列指向データベースにどのようなカラムファミリーを持たせるかはデータベース設計時に決めておく必要がありますが,カラムファミリーの中のカラムはデータに応じて柔軟に追加することができます.
列指向データベースは,関係データベースのように複数のレコードを横断して集約するような問い合わせには向いていません. また,データの整合性の担保も難しいです. しかし,キーとカラム名によって高速なデータ処理が可能,スケールアウトが可能といったメリットがあります. 代表的なワイドカラムデータベースとしては,Google Bigtable,Apache Cassandraなどがあります.
Note
もう1つの列指向データベース
実は,ワイドカラムデータベースとは別に,カラムナーデータベース(columnar database) と呼ばれる列指向データベースがあります. 両者は区別せずに語られることがあり,注意が必要です.
下図のように,カラムナーデータベースでは表形式のデータを列ごとに記憶装置に格納します. 記憶装置の特性上,カラムナーデータベースは同じ列に格納された値の集計演算を高速に行うことができます. 行か列かの些細な違いに思えますが,関係データベースのような行指向のデータベースで集約演算を行う際には,いったんは注目しない列(属性)の値も読み込むため効率が悪いです. そのため,列ごとの集計演算を頻繁に行う場合は列指向データベースが適しています.
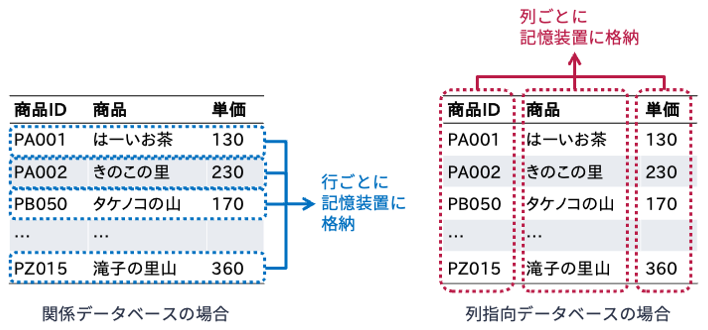
カラムナーデータベースはNoSQLとは位置づけられていませんが,ビッグデータ時代において非常に強力なツールです[2]. 代表的なカラムナーデータベースとしては,Google BigQueryなどがあります.
15.2.3. ドキュメント指向データベース#
関係データベースでは,テーブルのスキーマは設計時に確定させ,それを使い続けることが前提となっています. ところが,実際にサービスを運用し始めると,スキーマを修正したくなることがあります. また,データに応じて柔軟に補助的な属性を追加したいといったケースもしばしばあります. このようなケースで有用なNoSQLがドキュメント指向データベースです.
ドキュメント指向データベース(document-oriented database) は関係データベースにおけるレコードにあたるものを,XMLやJSON形式のドキュメントとして表現します. XMLドキュメントもJSONドキュメントもデータを木構造で表現したものですが,ドキュメント指向データベースはスキーマレスであり,どのような木構造でデータを表現するかはデータ投入時に柔軟に決められます. 以下の図は,2名の学生情報をXMLとJSONのそれぞれで表現した例です.

図を見ると分かるように,山畑滝子さんの氏名情報は姓名の区別なしに保存されているのに対して,川澄桜さんの氏名情報は姓名を区別して保存しています.
また,川澄桜さんの情報にはscholarshipのフィールドを追加して奨学金に関する情報を記録しています.
このようにドキュメント指向データベースでは,臨機応変にデータの構造を定義してデータを格納することができます. 代表的なドキュメント指向データベースとしては,MongoDBなどがあります.
15.2.4. グラフデータベース#
以下の図のように,グラフデータベース(graph database) は様々なデータをノードとエッジの2種類の要素を使って管理します. ノードはエンティティ(実体)を表し,エッジはエンティティ間の関係を表します. ノードもエッジもそれに関する情報を内部に持つことができます. なお,グラフとはノードとエッジから構成される数学的構造を意味します.
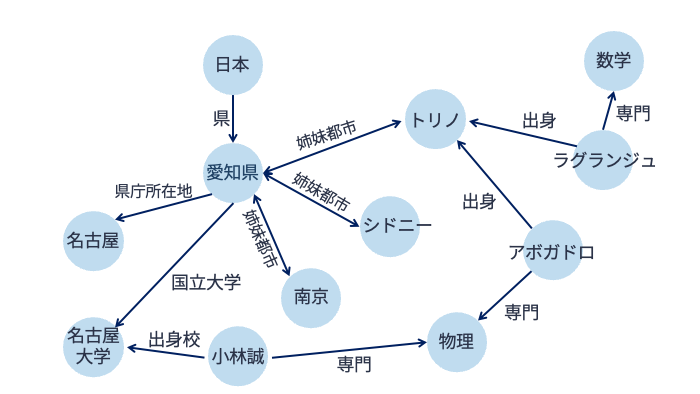
グラフデータベースは,エンティティ間にある多数の関係を表現するのに適しています. データ構造の特性と様々なグラフ探索アルゴリズムによって,グラフデータベースでは「トリノ出身で数学を専門とする人」といった複雑な問い合わせを高速に実現することができます. 代表的なグラフデータベースとしては,Neo4jなどがあります.