2. データベースの概念#
今日,データベースは様々な業務やアプリケーションで利用されています. 例えば,Amazonや楽天市場といったオンラインショッピングサイトにおいては,購買履歴管理や在庫管理を行うためにデータベースが用いられています. InstagramやTiktokといった,多数のユーザがコンテンツを投稿するソーシャルメディアにおいてもデータベースは欠かせません. 個人用ブログのような比較的小規模なウェブサイトでも,記事データを管理するためにデータベースが用いられています(例: WordPress). データを語る上で,データベースはなくてはならないものです.
本章では,データベースの概念を説明した後,最も代表的なデータベースであり,かつ本講義の主要テーマである関係データベース の概要について述べます.
Warning
データベースを学ばないデータサイエンティスト
データサイエンティストになりたいという学生が増えています. 最近はデータサイエンスに関する書籍もたくさん出版されています. インターネット上にも有益な学習コンテンツが無料で公開されていますし,Kaggleのような学習者のモチベーションをくすぐるデータ分析のコンペティションプラットフォームもあります.
そういったものを活用してデータ分析技術について学習している学生の中には,機械学習や統計モデリング等の分析技術はよく知っていても,データベースのことを分かっていない学生をちらほら見かけます. こういった人は,大規模なデータを自分で収集・管理・検索・整形したりすることができません. 当然ながら,データベースを設計することもできません.
それの何が悪いのでしょうか? データを管理している人がきれいなデータを用意してくれればよく,データサイエンティストはデータの分析技術を極めればよいのでは? そう思った方もいるかもしれません. たしかに,データ分析チームに必要なデータを用意してくれる専門家がいれば問題ありません. しかし,データ分析基盤を用意する専門家であるデータエンジニアがチームにいるのは,データ利活用文化が浸透している先進的な組織です. そうでない組織においては,組織内にあるデータベースに格納されたデータを分析者自ら収集する必要があります.
データを管理する人材が乏しくても,組織内できちんとデータベースが整備されている場合はマシです. しかしながら,データ分析プロジェクトが立ち上がったものの,
データ分析基盤は用意されていない
分析対象となるデータも分析可能な形で整備されていない
といったケースが,特に非IT企業や中小規模の組織では起こりえます(参考: 「データ分析失敗事例集」「実践的データ基盤への処方箋」). データ活用人材が不足する業界においては,こういった事態を打開することが「データサイエンティスト」には(暗に)期待されています.
上記のような理由から,データ分析を学ぶ学生にとってデータベースを学ぶことは大いに重要です.
2.1. データベースとは#
データを収集・利用する文化が根付いてきたこともあり,データベースという言葉が市民権を得つつあります. しかし,「データベース」という語が指す意味は,一般人とIT屋とは大きく異なります. 一般人にとってのデータベースとは,「データの集まり」くらいの意味です. 一方,IT屋にとってのデータベースは,
複数の応用目的での共有を意図して,組織的にかつ永続的に格納されたデータ群(北川博之著「データベースシステム」より)
あるいは
データの正しさを管理する主体によって体系的に整理され,計算機によって永続的に格納されたデータの集まり(吉川正俊著「データベースの基礎」より)
を意味します. 特に「データの正しさを組織的に管理する」という概念が重要です.
データベースを扱うためのシステムは,データベース管理システム(database management system, DBMS) と呼ばれます. 本来データベースとはDBMSによって管理されるデータ群を指しますが,DBMS(あるいはDBMSとそれによって管理されるデータ群)のことをデータベース(DB)と呼ぶこともあります.
増え続ける多様かつ大量のデータと付き合っていくためには,データのうまい管理・処理方法が必要になります. 場当たり的にデータを作ってはExcelシートやフォルダ(ディレクトリ)に突っ込んでおくというやり方は,扱うデータが増え,データを使う人間やアプリケーションが増えるにつれて,やがて破綻します. IT屋が考えるデータベースは,こういった事態を未然に防ぐための強力なツールです(★Quiz1★).
2.1.1. データ処理の際に求められる機能#
大量のデータを管理・処理する際には,以下のような要件が求められます.
2.1.1.1. 多様かつ大規模なデータの管理#
ビジネスをはじめとする現場では,多種多様かつ大量のデータが時々刻々と発生しています. 例えば,2020年1月1日から2020年12月31日までの12か月間に,Amazon.co.jpで購買された商品の数は5億点以上にのぼるとされています(出典).
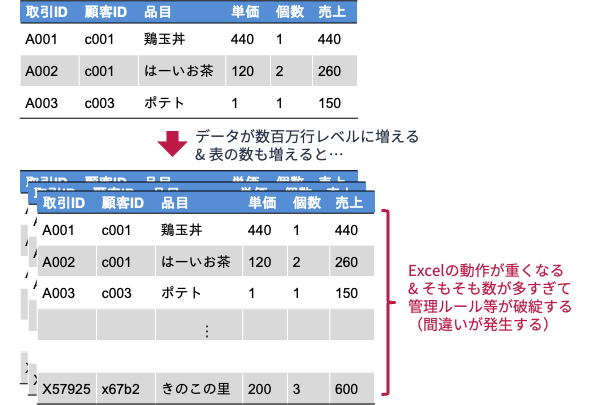
小規模な表データであれば,Excelのような表計算ソフトでも対応できます. しかし,データの規模が大きくなり,さらに表データの登録・更新を担当する人員が増えていくと… データの管理が破綻するのは想像に難くありません(そもそもExcelは1つの表につき最大100万行程度しか扱えません). Excelのようなスプレッドシートでは,購買データのように多様かつ大規模なデータを効率よく集積,管理することは困難極まりません.
2.1.1.2. データの正しさの保証#
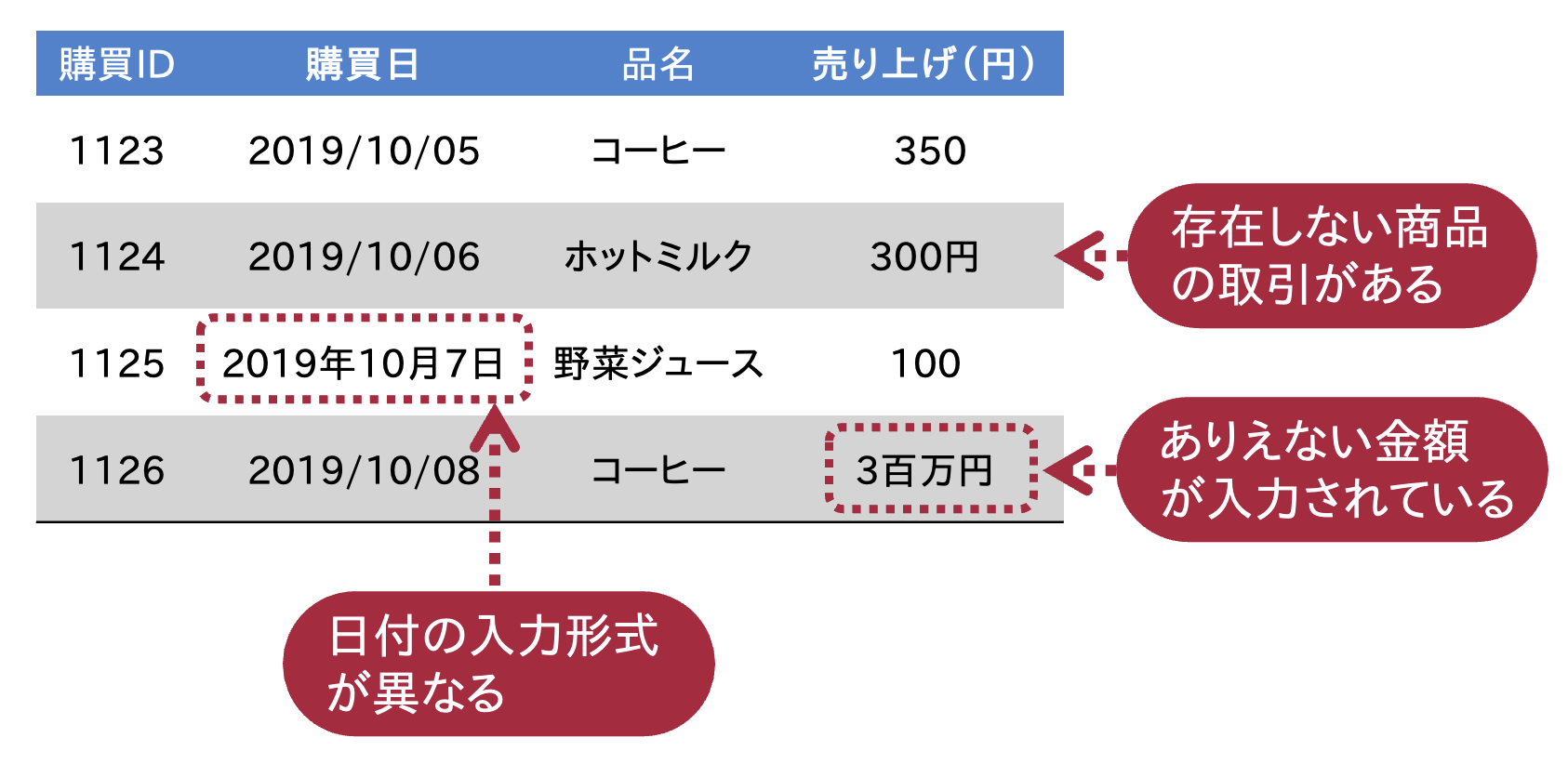
管理するデータが大量かつ多様になってくると,データを正しく保つことが難しくなってきます. 管理対象となるデータに誤りが混入すると,大変なことになります. 例えば,下の図のように,購買データの中に
現実にはあり得ない売り上げ金額が記録されている
入力形式が異なる日付が混在している
取扱商品リストにないはずの商品が購買履歴に含まれている
といったことが起きると,オンラインショッピング事業においては一大事です. それゆえ,データ管理においては,格納されるデータの正しさ,データ間の矛盾のなさを保証する機能が求められます.
2.1.1.3. 高速で効率的なデータ処理#
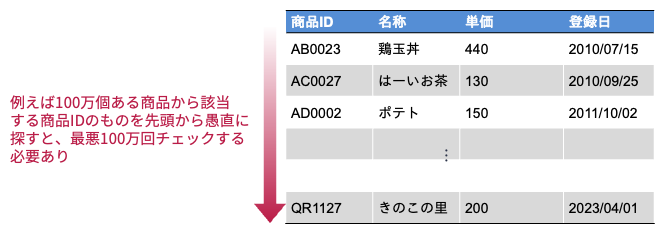
データが大量に格納できたとしても,対象となるデータを高速に処理できなければ使い物になりません. たとえ数百万件の書籍情報を格納しているシステムがあっても,ニーズを満たす書籍リストの検索結果を出力するのに数分待たされるようでは,そのようなシステムは使われません.
ユーザが増えるに従って,システムにかかる負荷も増えます. 例えば,Amazon.co.jpでは毎分平均900件以上の商品取引が行われています(出典). このように大量のデータのやりとりが発生するケースにおいても,高速にデータ処理されることが求められます(★Quiz2★).
2.1.1.4. 同時実行(並列処理)#
関連して,大勢の人が同時にデータを検索,追加,更新,削除しても,システムが問題なく動作することも重要です.
例えば,Xさん,Aさん,Bさんがとあるネット銀行の口座を利用しているとしましょう. Xさんの口座残高は100万円であるとします. 振り込みがあった際,振込先口座の残高の計算は
残高 = 振り込み時の「振込先口座」の残高 + 振込額
振込元口座の残高の計算は
残高 = 振り込み時の「振込元口座」の残高 - 振込額
となります.これは至極当然の処理ですが,次のような状況を考えてみましょう.
ある日,AさんとBさんがXさんの口座に一秒の狂いもなく,まったく同時に10万円送金したとします. この際,先の計算式をそのまま適用すると,以下の図のような処理になります.
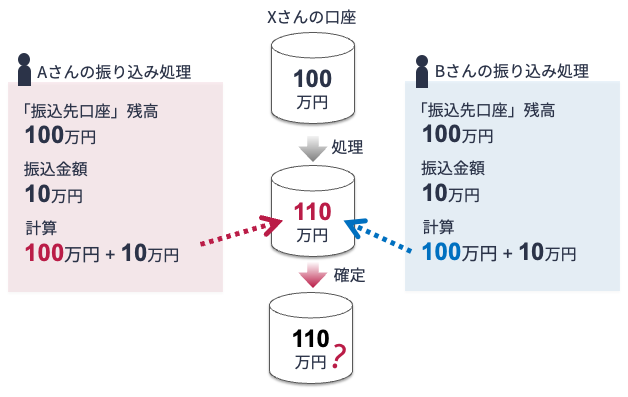
AさんとBさんが振込みを行った後,Xさんの口座の残高は110万円になりました – こんなことが起きたら大変です. この例における問題点は,たとえ振込み処理が同時に発生したとしても,Aさんの振り込み処理を待ってからBさんの処理を行うべきであったという点です.
このように,データ処理の内容によっては,別の処理が完了したことを保証してから次の処理を行う必要があります. さらに,処理の途中で何らかのエラーが起きた場合は,すべての処理をキャンセルして最初の状態に戻すことが求められます. 同時にアクセスがあった場合でも,データを矛盾なく処理できることが重要です.
2.1.1.5. アクセス権限のコントロール#
データによっては,誰でも自由に閲覧してよいものもあれば,特定の立場のユーザしかアクセスできないようにすべきものも存在します. 多種多様なデータのやりとりが発生する環境においては,ユーザの属性ごとにデータの閲覧,作成,更新,削除といったアクセス権限を制御する機能が必要となります.
2.1.2. データベースを用いるメリット#
一人で扱えるほどデータの規模が小さければ,Excelなどの表計算用のソフトウェアでデータ管理しても問題はありません. しかし,扱うデータが多様かつ大規模になると,要求されるデータ処理の質が変わります. そのため,データの管理方法や処理方法を見直す必要があります.
本稿で学ぶデータベースを用いれば,データの一元管理が可能となり,データ管理・データ利活用における様々な恩恵を受けられます. 具体的には,データベースが備える以下のような特性あるいは関連技術を用いることで,前節で述べた「データ処理に求められる要件」をクリアすることができます(★Quiz3★,★Quiz4★).
大規模なデータの管理:「物理的データ格納方式」の工夫によって対応
データの正しさの保証:「一貫性制約」によって対応
高速で効率的なデータ処理:「索引づけ」「問い合わせ最適化」などで対応
同時実行,データの共同利用:「トランザクション」などで対応
アクセス権のコントロール:「ロール管理」によって対応
Note
データ独立化:データとアプリを切り離す
データを処理する何らかのアプリケーション(以下,アプリ)を開発する場合,データベースを使わず
ファイルにデータを書き込むこと
アプリのコードの中にデータやデータの定義,データ処理方法を埋め込むこと
で対応することも考えられます. このようなアプローチは,アプリ開発やデータ分析の初心者が陥りやすい発想です. 処理するデータが小規模であったり,ユーザがアプリをインストールしている計算機の所有者に限定されるなどの場合は,上記のような対応でもなんとかなります. しかし,わたし自身も経験がありますが,
複数のユーザに同時に利用してもらうアプリを開発する場合,
蓄積したデータを複数のアプリケーションで共有して使い回す場合(例:ユーザ情報をショッピングサイトやメールサイトで使い回す),
データをファイルで管理したり,プログラムコードの中に埋め込む形式では,「データ処理の際に求められる機能」で述べたような不都合が生じることに気づきます.
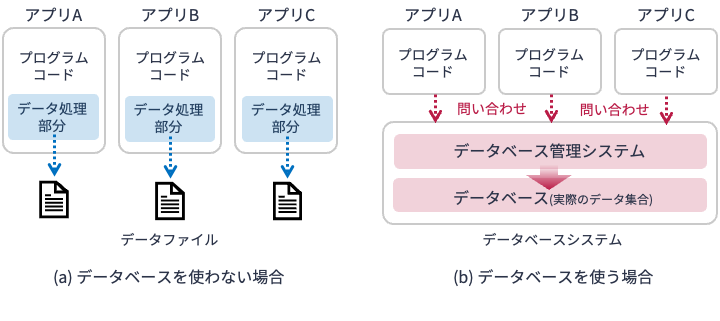
データベースを使うと,アプリケーションからデータを切り離すことができます. データベースはデータの処理・管理方法を一元化する(データの形式や処理の部分を一手に引き受ける)ことで,アプリケーションやデータ分析のコードから冗長な箇所を排除することができます. それによって,
ソフトウェア開発者はアプリケーションの開発,
データ分析者はデータの分析処理
に集中することが可能となります. また,同じデータが何度も作られる,正しくないデータが作られるということも減るので,データそのものの寿命も延び,データベースの価値も高まるのです.
2.2. “データ”のモデリング#
2.2.1. モデリングとは?#
科学やビジネスの世界では,モデルあるいはモデリングという用語がしばしば登場します. ビジネスプロセスモデル,物理モデル,統計モデルなど,世の中には様々なモデルが存在します. モデルとは,複雑な仕組みや現象,状態などを表現・分析・操作しやすくするために,本質的でない要素を取り除き,関心のある側面のみを抽出し抽象化したものです. モデリングとはモデル化,つまりモデルを作る行為です.
2.2.2. データモデリング#
データベースで何らかのデータを扱う場合,まずデータをモデリングします. 世の中に存在するデータは多種多様であり,データを統一的に整理し,計算機で処理しやすい形に抽象化,すなわちモデリングする必要があります.
データモデリングとは,データベース化すべき情報を取捨選択し,対象とするデータとその操作に関する枠組み(データモデル; data model)を設計する行為です. 対象とする事象やアプリケーションに応じて適切なデータモデルを設計することで,データモデルに従って実データを格納し,操作することが可能となります.
一般に,データモデルは以下の3つの要素を含みます:
データの構造
データの制約条件
データの操作
本講義の主要テーマである**関係データベース(relational database)**は,関係データモデル(relational data model) [1]に基づき設計されたデータベースです. 関係データモデルの詳細については,次講で説明します.
データベース管理システムで扱われるデータモデルとしては,関係データモデルのほかにも以下のようなものがあります:
ネットワークモデル
階層型データモデル
オブジェクト指向モデル
キー・バリュー(key-value)モデル
グラフデータモデル
2.2.3. 関係データモデル(導入)#
関係データモデルは,最も代表的なデータモデルです. 1970年にEdgar F. Coddにより提案されたもので,単純ながらその背後には強力な数学的基盤をもちます(★Quiz5★). 関係データモデルでは,あらゆるデータを**表(table)**としてモデル化します.
以下の図は,関係データモデルを用いて構築された,授業の履修状況・成績を管理する関係データベースの例です. この関係データベースには,以下の3つの表[2]が存在します.
学生テーブル:学籍番号,氏名,入学年度,所属といった学生に関する情報を格納
科目テーブル:科目ID,科目名,開講年度といった科目に関する情報を格納
履修テーブル:どの学生が何の科目を履修し,どのような成績であったかに関する情報を格納
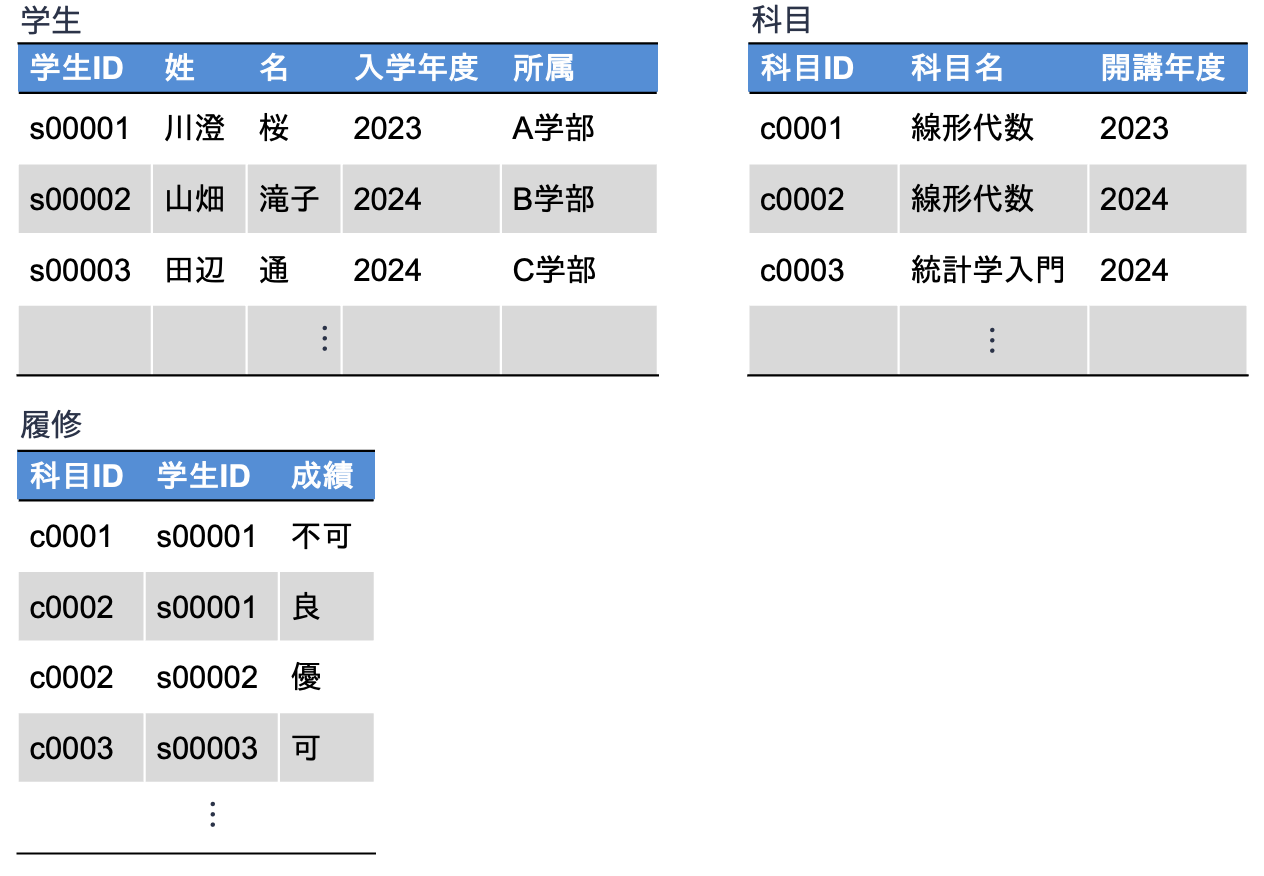
この例だけ見ると「なんだ,関係データモデルとは単なる表なのか」と思われたかもしれませんが,ただの表ではありません. 関係データモデルに基づいて表現された(表)データは,あらかじめ定義された「データの構造」「データの制約」「データの操作」に関する規則に従ってデータが作られ,関係データベース内に格納されます. 例えば,以下のような規則が考えられます:
学生テーブルは「学生ID」「姓」「名」「入学年度」「所属」という見出しをもつ
履修テーブルには,科目名や学生の氏名を格納しない
履修テーブルの成績には「優」「良」「可」「不可」のいずれかしか登録できない
履修テーブルに現れる科目IDおよび学生IDは,必ず学生テーブルと科目テーブルに存在する
学生テーブル,科目テーブルの各テーブルにおいて,同じ科目IDは存在しない
このような規則に従い,授業の履修状況や成績を管理するための情報が,複数のテーブルに分割され格納されます.
次講以降では,
このような規則,すなわち関係データモデルをどう設計するのか
一見ただの表にしか見えない関係データモデルが,どのように数学的に定式化されているか
関係データモデルを用いると,なぜ大規模データの管理が効率的になるのか
などについて詳しく述べていきます.
2.3. クイズ#
2.3.1. Q1. メジャーなデータベース管理システム#
ウェブ検索エンジンを用いて,世の中にあるメジャーなデータベース管理システムを調べよ. また,調べたデータベース管理システムを「関係データベースを扱うもの」と「そうでないもの」に分類せよ.
2.3.2. Q2. 線形探索#
100万件ある商品リストの中に特定の商品が含まれているかを確認したい. 商品リストの先頭から末尾まで順に商品名を確認していくと,平均で何回(何件)の確認で商品の有無を確認できるか?
2.3.3. Q3. データベース管理システムの利用例#
普段利用しているサービスのうち,データベース管理システムを用いていると思われるものを3つピックアップせよ.
2.3.4. Q4. CSV/TSVファイル#
CSVファイルおよびTSVファイルとは何かを調べよ. また,(データベース管理システムでデータを管理する場合と比較して)CSV/TSVファイルに存在する欠点を挙げよ.
2.3.5. Q5. チューリング賞#
関係データモデルを提唱したEdgar F. Codd氏は,計算機科学分野のノーベル賞といわれるチューリング賞の受賞者である. Codd氏以外で,データベースに関する功績でチューリング賞を受賞した人をピックアップせよ.