14. B+木 & ハッシュ索引#
第11講と第12講で説明した正規化理論によって,データの正しさを担保する関係データベースを設計することが可能となります. しかし,データの正しさが保証されても,問い合わせにかかる待ち時間が長いようでは,データベースとしての利便性は低いです. 利便性が高いデータベースには,データの管理のしやすさに加え,データの処理速度も求められます.
データベースの応答速度(クエリ実行時間)を改善する方法としては,クエリ最適化(query optimization)や索引の利用が考えられます. 本講では索引づけに焦点を当て,データベースの応答速度を改善する手法について述べます.
14.1. 関係データの物理的な格納方法#
計算機ではあらゆるデータはゼロイチの2進数で表現され,主記憶装置(メモリ)やハードディスクやSSDのような補助記憶装置のどこかに物理的に格納されます. 関係データベースにおいてもそれは同じです. 関係データベースではすべてのデータは表形式で表現されますが,データを補助記憶装置に格納する際には,表データはタプル(レコード)をひとまとまりの単位として分割され,記憶装置のどこかに格納されます.
Note
表データをタプル(レコード)単位で分割し格納するデータベースは行指向データベース(row-oriented database) と呼ばれます. それに対して,属性(列)単位で分割・格納するデータベースは列指向データベース(column-oriented database) と呼ばれます.
関係データベースのようにレコードの追加や削除を頻繁に行うことが想定されるデータベースにおいては,行指向でデータを格納するほうが効率的です. 一方,データの更新が頻繁でなく,属性(列)単位の集約演算を頻繁に行うような場合は,列指向データベースの方が効率的です.
以下は,関係「商品」を(物理的な)記憶媒体に格納する際のイメージ図です. 図のように,「商品」の各レコードは記憶装置の特定の場所にばらばらに格納されます. SQL文による問い合わせが行われると,関係データベースシステムは条件に合致するレコードが記憶装置のどこに保存されているかを調べ,該当する場所から具体的なデータを取得します.

14.2. 索引#
データベースから条件に合致するレコードを探す方法として,該当するテーブルのレコードが格納されている場所を先頭から1つ1つ調べ上げる方法が考えられます. この方法では,レコードの数がN件ある場合,N回確認作業が必要となります. 問い合わせへの応答時間は,確認回数に比例して長くなります. レコードの数が少ない,つまりNが小さい場合は問題とならないかもしれませんが, 関係データベースが対象とするデータ(レコード)の数は膨大です. 計算が得意な計算機とはいえ,数百万,数千万のレコード数を逐次的にチェックするにはそれなりに時間がかかります.
索引づけ(indexing) は,レコードの探索時間を改善したいときに有効な方法の1つです. 一般に索引といえば,特定の項目が書籍中のどのページに掲載されているかをまとめ,項目順に並べたものをイメージします. 索引は書籍の末尾に掲載されていることが多いです. 下図のように索引を調べることで,全ページを見返さなくても自分が知りたい項目がどこのページに掲載されているかをカンタンに知ることができます.

データベースにおける索引も書籍のそれと類似した役割を持ちます. データベースにおける索引(インデックス; index) とは,データベース中のある属性に注目し,ある属性値を持つレコードを効率よく取得できるよう工夫された特殊なデータを意味します. 索引は
索引キー(index key) と呼ばれる検索対象となる属性の値,および
その値をもつレコードの場所を特定する情報(記憶装置の中でレコードが格納されている場所)
から構成されます.
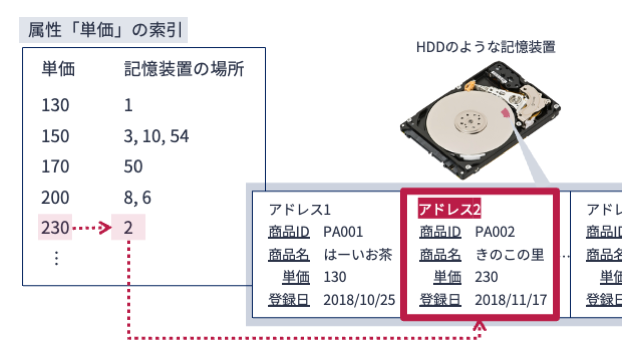
下図は関係「商品」の属性「単価」に関する索引,およびそれを利用した問い合わせのイメージです.
「単価」の索引には,単価の値(索引キー)とその値をもつレコードが格納された場所のペアが記載されています.
例えば,単価の値が230のレコードを検索したい場合は,索引を上から調べます.
値が230となるレコードが格納された場所が分かれれば,指定された記憶装置の場所を調べに行くことで所望のレコードの情報を得ることができます.
書籍における索引がそれのためにページが割かれているように,データベースの索引もそれ自体を作成するのに記憶装置の場所(空間)を消費します. 索引は空間効率を犠牲にして時間効率を向上させる方法です. 空間効率の劣化を抑えつつ時間効率を向上させるために,様々な種類の索引が提案されています.
14.3. 二分探索#
例えば,格納されたレコード数が10万の表に対して,ある属性に関する索引を構築したとしましょう. 索引のサイズ(索引キーの数)が索引付けの対象となる表の5分の1になった場合,索引の先頭から索引キーの値を調べていったとしても,合計2万回もの確認が必要となります(いわゆる線形探索). 索引を使えば,特定の条件を満たすレコードが探しやすくなる —— 直感的にはその通りなのですが,巨大な索引(キーのリスト)の中から条件に合致する箇所を探すには,効率の良い方法が必要となります.
索引キーがソートされている場合,索引の探索効率を劇的に向上させる方法として二分探索があります. 二分探索(binary search) は,ソート済みの配列から指定した値を高速に探索するアルゴリズムです. 二分探索アルゴリズムの概要は以下の通りです:
配列のちょうど真ん中の位置の値をチェックします.チェックした値が探している値の場合,そこで終了
チェックした値が探している値よりも
「小さかった」場合,配列の「右半分」を新たな検索対象配列とする
「大きかった」場合,配列の「左半分」を新たな検索対象配列とする
値が見つかるまで,ステップ1-2を繰り返す.配列の長さが1になっても見つからなかったら,探している値は配列にはなかったことになる
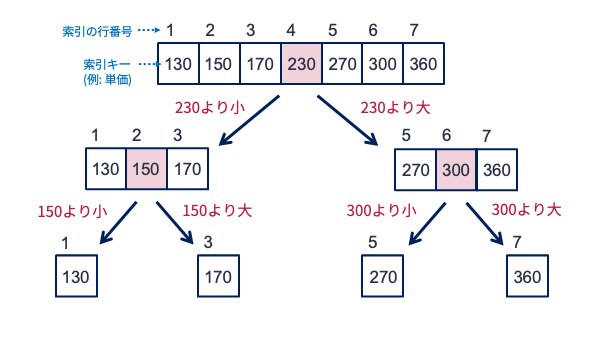
以下の図を使って,二分探索の振る舞いを確認してみましょう. 図の一番上には,ソートされた索引キーの配列が並んでいます. 配列の位置は索引における行番号と考えてください. 今,270という値(をもつレコード)の場所がどこかを知りたいとしましょう. 配列の先頭から愚直に調べると,270の値が入った場所を調べるには5回の確認作業が必要となります. 一方,二分探索を適用すると,以下のような手順で値の場所が見つかります.
まず配列の真ん中である4番目にアクセスし値を見る(値=230)
所望の値である270は230より大きいので,右半分の配列の真ん中の位置(6番目)にアクセスする(値=300)
所望の値である270は300より小さいので,先ほど確認した配列の左半分の真ん中(5番目しかない)にアクセスする
値が270であったので,位置情報として5を返す(終了して,索引の5行目に記されている記憶装置の場所にあるレコードを調べに行く)
270の値を見つけるのに要した配列へのアクセス回数は合計3回です. 二分探索では,1ステップごとに調査対象となる配列のサイズが半分になっています. そのため,もとの配列のサイズが\(N\)のとき,所望の値を見つけるために必要となる配列へのアクセス回数は最悪のケースでも\(log_2 N\)となります. 先の図の例では配列のサイズが小さいため二分探索の効果が感じにくかったかもしれませんが,配列のサイズが巨大になると二分探索の効果が実感できます. 例えば索引のサイズ(索引キーの種類数)が100万の場合,二分探索を使えば索引キーの配列に20回程度アクセスするだけで所望の値を見つけることができます.
14.4. B+木#
二分探索はソート済み配列を探索する上で強力な方法ですが,データベースの索引キーの探索に使うには,以下のような欠点があります.
データベースが超巨大になると索引のサイズも超巨大になるため,さすがの二分探索も少し遅くなる
属性値がある範囲の値をもつレコードを探索したいというケースにおいて,単一の値の検索に特化した二分探索は分が悪い
データベースではレコードの追加や更新が頻繁に発生するため,データベースの更新ごとに巨大な索引キーをソートするのは効率が悪い(クイックソートを使っても\(O(n \log n)\)の計算時間がかかる)
B+木(B+ tree)[1] は,二分探索よりも高速かつ効率よくデータの探索を行え,かつ更新にかかるコストも小さい,索引用のデータ構造です. B+木は以下のような特徴を持つ木構造データです(\(d\)および\(e\)の値は事前に決めておきます).
根ノードから葉ノードへのパスの長さはすべて同じである
葉ノードは索引キーの(順序付き)集合で構成される.各葉ノードは索引キーを収容するスペースをもつ.そのスペースには最小\(\lceil \frac{e}{2} \rceil\)個,最大\(e\)個の索引キーを収容できる.なお,葉ノード中の索引キーは昇順にソートされている
隣接する葉ノードはリンクで結ばれている(すぐ隣の索引キーが何か分かる)
葉ノード以外のノードは,ポインタと探索キーを交互に持つ.なお,ノードに収容できるポインタの数は最大で\(2d+1\)個,探索キーは最大\(2d\)個である.探索キー\(k\)の左隣のポインタは値が\(k\)未満の探索キーを含む子ノードにリンクしている.探索キー\(k\)の右隣のポインタは値が\(k\)以上の探索キーを含む子ノードにリンクしている
根ノードは1個以上の探索キーを持つ
根ノード,葉ノード以外の中間ノードは\(d\)個以上の探索キーを持つ
葉ノードの各索引キーはその値を属性値としてもつレコード集合とリンクしている(記憶装置で該当レコードが記録されている位置にすぐ飛べる)
なお\(d\)の値をB+木の次数 と呼びます.
上の定義だけでは分かりづらいので,図を見ながらB+木の特徴を確認しましょう. ある属性\(A\)の索引キー(属性値)として
1, 4, 9, 16, 25, 36, 49, 64, 81, 100, 121, 144,169, 196, 225, 256
のいずれかを取るレコードを格納したテーブルがあるとしましょう. 以下の図は,このテーブルの属性\(A\)に関するB+木です. なお,このB+木は\(d=1,e=3\)としています.
図を見たら分かるように,すべての索引キーはいずれかの葉ノードに格納されています(特徴2). 索引キーが格納されたどの葉ノードについても,根ノードから2回枝をたどるだけで到達できます(特徴1). また,根以外のどのノードも半数以上スペースが埋まっています(特徴2および4). さらに,ある索引キーの次に小さい(大きい)索引キーは同じ葉ノード内で隣接している,もしくは隣接する葉ノード内に存在します(特徴3). そのため,例えば索引キーの4の次に大きい索引キーを知りたければ,4が含まれる一番左の葉ノードから右隣にリンクされている葉ノードを見ることで,9が次に大きい索引キーであることが分かります.
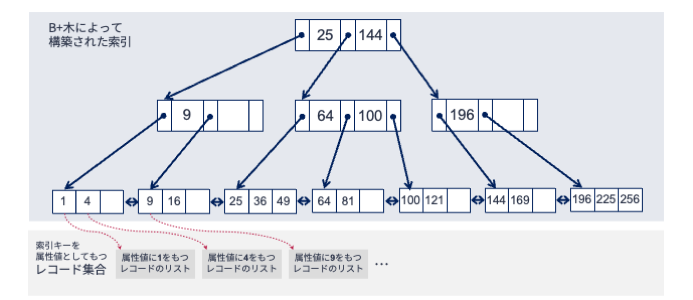
B+木では,葉ノードは各レコードの格納場所情報を保持しているため,いわゆる索引と見なすことができます. 一方,葉ノードの親ノードは葉ノードを振り分け,葉ノードの場所を管理しているという意味では,索引の索引になっていると見なせます. このように,B+木は索引を階層的に管理していると見なせます.
B+木で重要なことは,どの葉ノードも根ノードからの距離が同じであることです. これによって,どの索引キーも同じ計算時間で見つけることができます. 一方,どのノードも常に半数以上スペースが埋まっているという特徴は,裏を返せば半分は空いていてもよいということになります. これは索引に割り当てる記憶領域が無駄になっていることを意味しますが,空きがあれば木の構造を大きく変えずに新たな索引キーが挿入できるため,索引更新に柔軟性を持たせる工夫とも言えます. このようなB+木を索引に使うことで,ある条件にマッチするレコードを高速に探索することができます. また,レコードが追加・更新・修正されても,コストを抑えて索引を更新することができます.
以下では,B+木を用いたレコードの探索方法について見てみましょう.
14.4.1. B+木による値の探索#
ある属性値をもつレコードの探索は,ノードに含まれる探索キーをチェックしながらB+木の根ノードから葉ノードまでたどることで行います. 例えば,ある属性\(A\)の値として,
1, 4, 9, 16, 25, 36, 49, 64, 81, 100, 121, 144,169, 196, 225, 256
のいずれかを取るレコードが格納された関係表に対して,B+木による索引を構築したとしましょう(先の図がそれです).
このB+木を使って,属性\(A\)の値が121となるレコードを探すことを考えましょう.
手順は以下の通りとなります(図も参照してください).
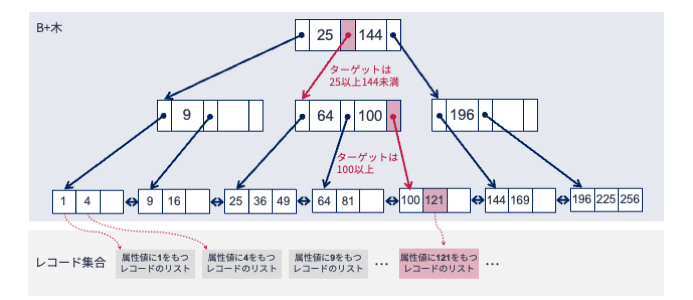
まず,根ノードにアクセスし格納された探索キーを調べます.
探索キーは25と144です.
ターゲットとなる値は121であり,25よりも大きく144よりも小さいです.
よって,探索キー25と144の間にあるポインタをたどります.
ポインタをたどった先にあるノードには,探索キーとして64と100が格納されています.
先ほどと同様,ターゲットとなる値と探索キーの関係を調べると,ターゲット値である121は100より大きいです.
よって,探索キー100の右隣にあるポインタをたどります.
その結果,葉ノードにたどり着きます.
葉ノードに格納された索引キーを左から探索すると,一番左端にターゲット値である索引キー121が見つかります.
所望の索引キーが見つかったので,そこからリンクされたレコードを取得します.
これにて探索完了です.
B+木の特徴6に記した条件により,B+木ではどの中間ノードも子ノードの数は\(d+1\)個以上となることが保証されています. これにより,索引キーの数が\(N\)の場合,B+木の根ノードから葉ノードへのパスの長さは\(log_d(N)\)となります. 各ノードに含まれる探索キーの数は高々\(2d\)個です. 各ノードを探索キーを線形に一通りチェックしたあとパスをたどるとしても,探索完了までにかかる計算量は\(d\)が\(N\)よりも十分小さいことも考慮すると,高々
\(O(2d \ log_d N) = O(log_d N )\)
となります. 二分探索を用いた場合の計算量は\(O(log_2 N)\)であるため,\(d\)を2より大きく取ればB+木は二分探索よりも高速に値を探索することができます.
14.4.2. 範囲探索#
B+木を使えば,範囲探索も容易に行えます.
先ほどの例で使ったB+木を使って,属性値がある範囲にあるレコードを探索する手順を示しましょう.
今,属性値が10以上40未満であるレコードをすべて取得したいとしましょう.
手順は以下の通りです(図も参照してください).
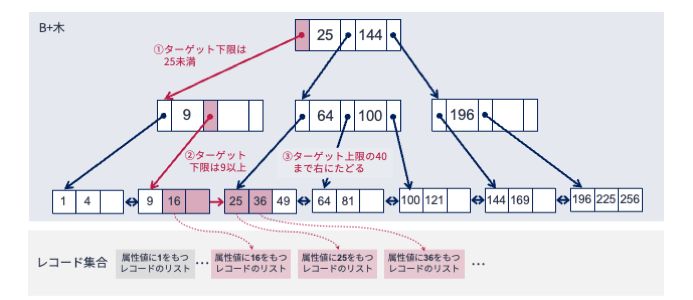
探索条件の下限である10に着目します.
根ノードにアクセスし格納された探索キーを調べます.
探索キーは25と144です.
ターゲットとなる値は10であり,25よりも小さいです.
よって,探索キー25の左にあるポインタをたどります.
ポインタをたどった先にあるノードには,探索キーとして9が格納されています.
ターゲット値は10であるため,探索キー9の右隣にあるポインタをたどります.
その結果,葉ノードにたどり着きます.
葉ノードに格納された索引キーを左から探索すると,左から2番目にターゲット値である10より大きい索引キー16が見つかります.
ところで,ターゲットとなる属性値の上限は40でした.
そこで,先ほど見つけた索引キー16から右側にリンクをたどりながら索引キーが40未満のものをすべて拾い上げていきます.
すると,索引キーとして16,25,36が見つかります.
条件を満たす所望の索引キーがすべて見つかったので,各索引キーからリンクされたレコードを取得します.
これにて範囲探索完了です.
14.4.3. B+木の構築・更新#
すでに述べたように,データベースではレコードの追加や更新が度々行われます. そのため,データベースの更新に応じて索引の更新も必要となります.
B+木は根ノードから葉ノードへのパスの長さが均一になるよう(木の高さのバランスを崩さない)よう,索引を更新するアルゴリズムが提案されています. 直感的には,
新たな索引キーを挿入する場合には,木の構造を崩して木を上に向かって伸ばす
索引キーを削除する場合には,キーの挿入操作の逆を行う
といった戦略でB+木を更新します. B+木の更新アルゴリズムの詳細については「IT Text データベースの基礎」「データベースシステム(改訂2版)」「リレーショナルデータベース入門(第3版)」などの書籍を参照してください.
14.5. ハッシュ索引#
B+木のような木構造の索引では,根ノードから葉ノードにまでたどることで,条件にマッチする属性値をもつレコードが格納されている場所を調べます. 探索を容易にするためにB+木ではその索引木構造に工夫をこらしていますが,\(O(log_m{N})\)の計算時間をかけて根から葉に向かって木をたどらなければなりません.
仮に,ある値が指定されたときにそれを属性値としてもつレコードの格納位置を「直接」知ることができれば,B+木よりももっとカンタンに求めるレコードを取得することができます. これを実現するのが,ハッシュ索引(hash index) です. B+木と同様,ハッシュ索引も探索範囲となる属性を指定して索引を構築します.
B+木と異なるのは,ハッシュ索引では索引キーの値とレコード(の格納場所)との対応付けを行うためにハッシュ関数(hash function) を用います. ハッシュ関数とは,任意の値を別の都合の良い値(ハッシュ値)に変換するための関数です. 良いハッシュ関数は値の変換にかかる計算コストが低くなるよう設計されています.
以下の\(mod_d(x)\)は整数\(x\)を整数\(d\)で割ったときの剰余(いわゆる余り)を計算する関数です. ただし\(q\)は整数とします.
剰余演算は高速に実行できることが知られており,ハッシュ索引を構築するためのハッシュ関数としてしばしば使われます.
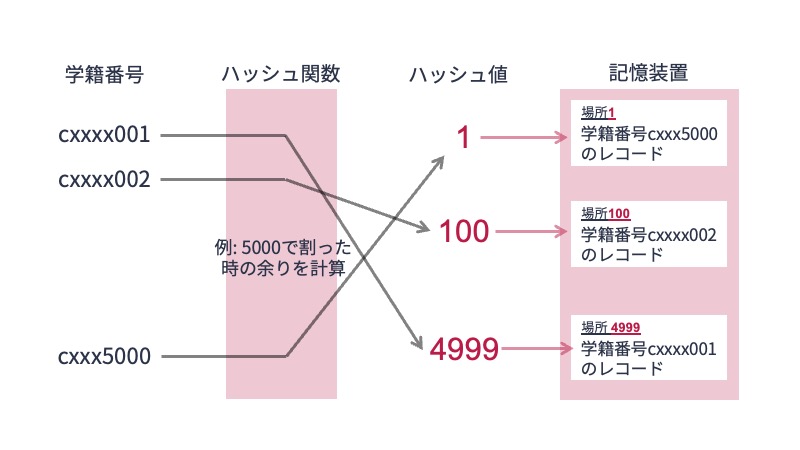
例えば,学生情報を格納するテーブル学生に対して,属性学籍番号の値を探索キーとするハッシュ索引を構築するとしましょう.
一般に学籍番号は数字以外の文字も含まれる文字列ですが,計算機の中では文字列も整数値で表現されているので,剰余を計算することは可能です.
そこで,以下の図のように学生テーブルの各レコードの学籍番号の値に剰余を計算する関数を適用し,得られた剰余値が示す記憶装置の場所にレコードを格納します.
このようにハッシュ索引を構築しておけば,レコードを取得したい学生の学籍番号から剰余値を1回計算するだけで,必要となる学生情報が格納されている場所を特定し,レコードを取得することができます.
高速にレコードを取得できるハッシュ索引ですが,致命的な弱点があります. ハッシュ索引は属性値がある範囲にあるレコードを見つける範囲探索にはまったく有効に機能しません. ハッシュ索引は各レコードの属性値のハッシュ値とレコードの格納場所を一対一対応させているにすぎず,探索キーの値が完全一致するものしか見つけられません. そのため,範囲探索が必要な属性に対しては,B+木のような索引を用いる必要があります.
14.6. SQLによる索引の構築#
大抵の関係データベース管理システムでは,以下のようなSQL文でテーブルの特定の属性に対して索引を構築することができます(「インデックスを張る」ともいいます).
CREATE INDEX インデックス名
ON テーブル名 (索引の対象となる属性名)
USING 索引種別;
例えばproductテーブルの属性priceに関してB+木を使った索引を構築したい場合は,以下のようなSQL文を使います.
CREATE INDEX product_price_idx
ON product (price)
USING btree;
一般に,主キーや外部キーとして指定された属性には自動的に索引が構築されますが,それ以外の属性に索引を構築したい場合は上記のようなSQL文を発行する必要があります. 問い合わせに対する応答速度が遅い場合,索引の構築は非常に効果的です. 一方,索引は記憶領域を余分に消費するので,無闇に索引を構築するのは避けるべきです.